|
В
журнале "Цифровое Видео"
№5, стр. 15-19 были
рассмотрены основные
характеристики восьми
актуальных плат
нелинейного монтажа,
предназначенных для
профессионального
видеопроизводства, от
трех ведущих фирм
производителей: Pinnacle Systems,
DPS и Matrox. При этом было
отмечено, что TARGA
3000 “на голову”
превосходит всех
конкурентов, предлагая
своим настоящим и
особенно будущим
пользователям
действительно уникальные
возможности цифрового
монтажа и композитинга. В
этом устройстве впервые
применены принципиально
новые технологические
решения, открывающие
следующую главу в истории
развития подобных систем.
В то же время,
справедливости ради
необходимо отметить, что в
этой бесконечной гонке
технологий фирма Pinnacle Systems
всего лишь опередила
своих конкурентов на
промежуточном финише. И в
ближайшее время стоит
ожидать “ответных ходов”
от DPS и Matrox, да и Pinnacle,
очевидно, не остановится
на достигнутом. Одним
словом, на наших глазах
происходит эволюционная
смена поколений плат
нелинейного монтажа.
Однако, несмотря на
очевидные различия в
конкретных схемах их
построения и
характеристиках
используемых цифровых
видеопроцессоров,
принципиально все эти
будущие решения должны
будут отвечать общим
требованиям,
соответствовать новому
уровню планки “для взятия”,
установленному
появлением TARGA 3000 (далее по
тексту T3K). Поэтому для
последующего понимания
основ их функционирования
автор считает важным
рассмотрение
особенностей организации
работы T3K - как первого
представителя нового
поколения, обещающего
быть уже завтра весьма
многочисленным.
Архитектура
обработки
Оглядываясь
назад, мы вынуждены
констатировать, что
большинство используемых
в настоящее время
цифровых систем обработки
видео, по сути, являются
всего лишь цифровой
адаптацией традиционной
концепции построения
старых аналоговых
монтажных систем. В них
несколько цифровых аудио
и видео потоков
последовательно проходит
через набор
спецпроцессоров,
обеспечивающих
выполнение в реальном
времени заранее заданных
преобразований,
предопределенных еще на
стадии разработки каждого
процессора. В качестве
примера достаточно
привести общую схему
построения линейки DigiSuite
от Matrox, в соответствии с
которой в популярной
плате DigiSuite LE для
параллельной обработки
двух видеопотоков
используются
соответственно два 2D-DVE
процессора Matrox Fiesta-II, для
работы с дополнительным
слоем графики - контроллер
Matrox MGA-2064SG, а собственно
микширование с переходами
выполняется в Matrox Siesta-II. А
вот в полной версии
собственно DigiSuite для
обеспечения большей
производительности число
процессоров Fiesta-II
увеличено до 5 штук.
Аналогичный вывод
справедлив и ReelTime/NITRO от
Pinnacle Systems, и для DPS Reality/Velosity
– для обеспечения новых
эффектов и/или увеличения
числа одновременно
обрабатываемых слоев
необходимо увеличение на
борту вычислительной
мощности, т.е. добавление
новых спецпроцессоров.
Так, преобразование Velosity 2D
в Velosity 3D путем установки
дочерней платы V3DX с
процессором 3D-эффектов
кроме всего прочего
добавляет еще один слой
графики.
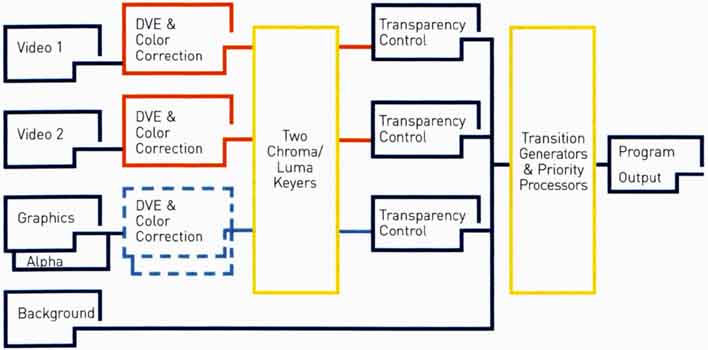
Однако
подобная последовательно-потоковая
обработка имеет свои
очевидные пределы, и не
позволяет, например,
удвоить или даже утроить
число слоев, поменять
порядок выполнения
операций или осуществить
многократное выполнение
одного и того же эффекта. К
тому же, все эти
процессоры разработаны
под определенный формат
видео (4:3), заданные
разрешение (720x576), цветовое
представление (YUV 4:2:2) и
глубину оцифровки (8-bit на
компонент). В то время как
мир стоит на пороге
реального внедрения
телевидения высокой
четкости, многие
программы уже сейчас
снимаются и выпускаются в
соотношении 16:9, а
композиционная сложность
современного видео
требует высокоточной
обработки в представлении
4:4:4:4 при 16-bit на компонент.
Одним словом, цифровые
платы, использующие
традиционную обработку
видео, “завтра” во многом
перестанут отвечать
требованиям времени.
Необходим новый подход к
организации процесса
обработки, более гибкий и
точный, позволяющий
быстро перестраиваться от
нужд “классического”
видеопроизводства к
потребностям “нового”
телевидения. Именно такое
решение и реализовано в T3K.
Теория
ее построения сводится к
следующим основным идеям:
-
использование
большого буфера
разделяемой памяти,
позволяющего
одновременно размещать
до десятка различных
кадров с произвольным
доступом к любой ячейке;
-
преобразование
входящих потоков видео
в массивы пикселей и их
размещение в буфере
памяти с возможностью
многократной записи/считывания
как исходных массивов,
так и результатов их
обработки;
-
возможность
задания в широких
пределах как размеров
исходных массивов, так и
битовой глубины их
отдельных ячеек;
-
и,
наконец, параллельное
задействование для
операций над массивами
пикселей нескольких
вычислительных
ресурсов, работающих с
быстродействием, в
несколько раз
превышающим real-time, и
позволяющих
зацикливание процесса
обработки.
Чтобы
подчеркнуть
принципиальное отличие
данного подхода,
специалисты Pinnacle Systems
придумали для него
специальное определение Memory-Centric
– против традиционного,
названного
соответственно Stream-Centric.
Здесь внимательный
читатель вправе
воскликнуть, что ничего
особенного в Memory-Centric нет,
ведь аналогичный подход
уже давно используется в
компьютерах общего
назначения для решения
самых обычных задач.
Действительно,
функционирование,
например, процессора Pentium
также немыслимо без
активного задействования
ресурсов оперативной
памяти (RAM). И подобный
компьютер действительно
можно в том числе
использовать для
видеопреобразований. Но в
этом случае придется
забыть о реальном времени
выполнения, поскольку
задачи обработки видео
столь специфичны и сложны,
что требуют специальных
вычислительных ресурсов.
Сердцем
T3K стал новый сверхмощный
видеопроцессор HUB3,
разработанный
специалистами Pinnacle и
производимый фирмой IBM по
0,25-микронной технологии. В
этом ASIC-микрочипе (Application
Specific Integrated Circuit)
объединены
многоканальный
программируемый
контроллер (интерфейс)
памяти, обеспечивающий
суммарную пропускную
способность до 1,5 ГБ/сек,
по пять независимо
контролируемых портов
ввода и вывода аудио/видео
информации, каждый с
собственным DMA-доступом (Direct
Memory Access) к интерфейсу
памяти, и два
специализированных
вычислительных блока с
производительностью 100
Мпиксел/сек каждый. Первый
из блоков, RCL (Resizer / Color
Converter / LookUpTable), выполняет
двумерное геометрическое
преобразование входного
кадра (выделение
фрагмента, задание нового
размера и положения и т.д.),
затем его матричное 3x3
цветовое преобразование в
представлении YUV или RGB, и
по завершению – линейную
цветокоррекцию через LUT-таблицу
из 1024 значений. Второй
вычислительный блок, 4-Layer
Compositor, принимая 4 исходных
изображения (кадра),
сначала производит
независимые
геометрические
преобразования первых
трех (относительное
смещение и обрезание, но
не масштабирование), а
затем – их послойное
микширование (наложение
друг на друга с учетом
задаваемой прозрачности).
При необходимости, этот
блок также аппаратно
выполняет Chroma-Key операцию,
активно используемую для
построения виртуальных
сцен.
Теперь
оценим реальное
быстродействие HUB3.
Согласно стандарта ITU-R 601
телевизионный кадр - это 415
тысяч пикселей (720х576), что
при глубине цветового
представления в 2 байта на
пиксел (4:2:2) соответствует
810КБ. Ну а поскольку
кадровая частота равна 25
Гц, то цифровой поток
некомпрессированного
видео – это 10,4 миллиона
пикселей или 20 МБ в
секунду. Таким образом, за
1/25 сек – “время жизни”
real-time процессов –
стандартный кадр можно
успеть 75 раз записать/считать
в буфер памяти, или,
другими словами,
пропускная способность
контроллера памяти HUB3
составляет 75 потоков
видео! В то же время каждый
из вычислительных блоков
за 1/25 сек позволяет
выполнить до 8 циклов
соответствующей
обработки потоков (теоретический
предел 100/10,5 равен 9, но
часть времени теряется на
служебные установки,
переключение режимов и т.д.),
и, например, произвести в
real-time 32-слойный
композитинг и
цветокоррекцию 8 потоков!
HUB3
также включает в себя
собственный 64-битный PCI
интерфейс, работающий на
частоте 33 МГц и
обеспечивающий скорость
обмена данными между
буфером памяти T3K и
системной памятью
компьютера и накопителями
информации на жестких
дисках до 200 МБ/сек. С этой
точки зрения T3K может
оперировать с 10 потоками!
К сожалению, здесь весьма
серьезным ограничением
становятся возможности
собственно дисковой
подсистемы компьютера,
вынужденной при чтении
переключаться между
записями различных
потоков. Считая среднее
время поиска/переключения
на диске равным 5 мс и
размер кэша чтения равным
1 МБ, легко вычислить, что
уже при 5 потоках каждую
секунду половина времени
будет теряться именно на
поиск требуемых записей (5
потоков x 20 раз x 5 мс), так
что эффективная скорость
передачи данных упадет
вдвое. Для многопотоковых
систем монтажа это очень
серьезная проблема, над
разрешением которой в
настоящее время работают
во многих фирмах, например,
в корпорации Medea. Один из
очевидных выходов – в
уменьшении требуемой
пропускной способности за
счет сжатия видео. На T3K
установлены два кодека
DVXpert фирмы C-Cube,
обеспечивающие 2
параллельных канала для
компрессии и 4 для
декомпрессии и
поддерживающие стандарты
как MPEG-2, так и DV25 (с
возможностью
программного upgrade до DV50).
Таким образом,
принципиально T3K уже
сегодня могла бы работать
по крайней мере с 5
потоками, и при испытаниях
специалистам Pinnacle Systems
действительно это
удавалось. Но в настоящей
версии программного
обеспечения для
обеспечения надежной
работы и снижения
требований к базовой
компьютерной системе пока
наложено ограничение в 3
потока
некомпресссированного
видео и в 2 –
компрессированного (и
дополнительно до 5 или 6
слоев графики
соответственно).
Как
уже отмечалось, HUB3 имеет 5
независимых портов ввода/вывода
информации. Первые два
соединены с кодеками DVXpert,
один порт зарезервирован
для встроенного разъема
расширения AVIO,
предназначенного для
подключения к T3K будущих
дочерних плат (например,
платы 3D эффектов Infinite 3D), а
оставшиеся два порта
используются для связи с
внешним блоком разъемов (BOB
– Break-Out-Box), через который
собственно и происходит
передача входной и
выходной информации.
Таким образом, плата T3K в
состоянии осуществлять
одновременную запись и
воспроизведение
различных потоков,
многоканальное
независимое проигрывание
цифровых файлов,
микширование в real-time
живого видео и цифровых
файлов и т.д. К сожалению,
настоящая версия
программного обеспечения
(Adobe Premiere или Speed Razor) не
позволяет
воспользоваться этими
возможностями, оставляя
их реализацию для более
продвинутых приложений.
Поэтому в T3K пока
задействован только один
из двух портов связи с BOB.
Также
с запасом на будущее в
данной архитектуре
заложены возможность
программного изменения
кадрового разрешения,
частоты и порядка
развертки, аспектного
отношения, структуры и
глубины представления
данных. Это превращает T3K в
идеальную рабочую лошадку
для решения самых
разнообразных задач
завтрашнего дня, от
подготовки программ
телевидения высокой
точности до web-вещания.
Блок
внешних соединений
|
Типы
сигналов и число
разъемов, требуемые
для профессиональной
платы монтажа
|
|
Тип
сигнала
|
Вид
разъема
|
Вход/выход
|
|
Composite
Video
|
BNC
(RCA)
|
1/1
|
|
S-Video
(Y/C)
|
4-pin
mini-DIN
|
1/1
|
|
Component
Video
|
3
x BNC
|
1/1
|
|
DV
|
4-pin
(6-pin) IEEE-1394
|
1
|
|
SDI
Digital Video
|
BNC
|
1/1
|
|
Unbalanced
Audio
|
2
x RCA
|
1/1
|
|
Balanced
Audio
|
2
x XLR
|
2+/2+
|
|
S/P
DIF Digital Audio
|
RCA
|
1/1
|
|
AES/EBU
Balanced Audio
|
XLR
|
2+/2+
|
|
AES/EBU
Unbalanced Audio
|
BNC
|
1/1
|
|
TDI/F
Digital Audio
|
DB-25
|
1
|
Проблема
обеспечения качественных
соединений встроенной
платы компьютера с
внешними устройствами
остро стоит перед
производителями уже много
лет. Спецификация PC-компьютеров
оставляет на внешней
планке платы очень
небольшое пространство
для размещения всех
соединений. В то же время
современные
профессиональные
устройства обязаны
поддерживать самые
разнообразные типы видео (Composite,
S-Video, YUV (RGB), DV, SDI), так и
аудио (небалансный,
балансный, AES/EBU, S/PDIF, TDIF)
сигналов, общим числом
соединений более 30 (см.
табл.2), причем это число с
развитием видов вещания
только возрастает.
Сложность проблемы не
столько в высокой (и
возрастающей) плотности
вывода контактов на
задней планке, но и в
размещении на самой плате
необходимых микросхем
приема и обработки (оцифровки,
кодирования)
соответствующих сигналов,
в исключении их взаимного
влияния (наводок), и в
конце концов – в
последующей надежной
работе. Ведь известно, что
наиболее часто
возникающая при
эксплуатации
неисправность – “сгоревшие”
входы-выходы (из них не
менее чем в 50% случаев –
композитные).
Известны
различные подходы к
решению задачи соединений.
Самый прямой и дешевый с
точки изготовления самой
платы – интеграция на
заднюю планку
специального разъема
высокой плотности (до 40
контактов) и комплектация
платы соответствующим “хвостом”
кабелей. Недостатки этого
подхода общеизвестны:
частичное отражение
принимаемых
электрических сигналов из-за
невозможности полного
согласования входных
импедансов и неизбежные
наводки по общей “земле”,
неудобство эксплуатации
тяжелого и негибкого “хвоста”
(при частых соединениях
возникает опасность
механического
повреждения разъема на
плате или проводки в одном
из кабелей), да и
дороговизна собственно
его изготовления (как
правило, требующей ручной
пайки). Развитием данного
подхода является
использование различных
внешних блоков (BOB – BreakOutBox),
на которые собственно и
вынесены все необходимые
разъемы. Такой BOB является
своеобразным пассивным
удлинителем, делающим
более удобным и
безопасным соединение
платы с внешней аудио-видео
аппаратурой. Однако, с
точки зрения качества
передачи сигналов, для
него характерны те же
проблемы.
Существенно
более прогрессивным
является использование
активного BOB, в который
вынесена часть
необходимых операций
обработки входных и
выходных сигналов: их
прием, аналого-цифровые
преобразования,
фильтрация и
декодирование. В этом
случае передача
информации между BOB и
платой вне зависимости от
конкретного типа внешнего
сигнала осуществляется
уже в едином цифровом виде
(например, компонентный
для видео и балансный для
аудио). При этом размеры BOB
позволяют развести цепи
обработки аналоговых
сигналов и обеспечить их
качественные прием и
преобразование. Одним из
важных следствий данного
подхода является
освобождение платы от
рутинных операций
оцифровки и освобождение
пространства на ней для
размещения
дополнительных
специализированных
микросхем -
вычислительных блоков
эффектов. Привлекает и
унификация устройств –
один и тот же BOB может быть
в дальнейшем использован
для “подготовки”
сигналов для других плат,
и, наоборот, для
расширения списка
поддерживаемых сигналов (внешних
устройств) или повышения
точности их
преобразования
достаточно к существующей
плате подсоединить новый
BOB. Следующим шагом в этом
направлении становится
объединение в одном BOB
приема как аналоговых, так
и цифровых сигналов. Кроме
собственно удобства
соединений это
принципиально позволяет
осуществлять в рамках BOB
преобразования типов
сигналов, например, из SDI
получать аналоговое
компонентное видео, из
S-Video – SDI.
|

|

|
|


